
Microsoft has unveiled a new text-to-speech AI model called VALL-E which can accurately simulate anyone’s voice with just a three-second audio clip of them speaking.
As reported by Ars Technica, the software giant’s researchers have demonstrated VALL-E in action in a new research paper and GitHub demo. Although it's still in its infancy, VALL-E is already impressing the scientific community — and creeping out the rest of us — with its ability to synthesize audio of a person saying anything while preserving their emotional tone.
VALL-E’s creators believe that their new AI model could one day be used in text-to-speech software, to edit pre-existing recordings and even to create new audio when used alongside other AI models like GPT-3.
According to Microsoft, VALL-E is a “neural codec language model” that builds off a technology from Meta called EnCodec announced back in October of last year. It sets itself apart from other text-to-speech methods by generating discrete audio codec codes from text and acoustic prompts as opposed to manipulating waveforms to generate speech.
Synthesizing personalized speech
In order to synthesize personalized speech, VALL-E generates acoustic tokens after listening to a three-second clip of a person speaking and then uses them to “synthesize the final waveform with the corresponding neural codec decoder” according to Microsoft’s researchers.
To train its new AI model, the company’s researchers used an audio library from Meta called LibriLight. The library itself is made up of 60,000 hours of English speech from over 7,000 speakers though most of this recorded speech was pulled from public domain audiobooks.
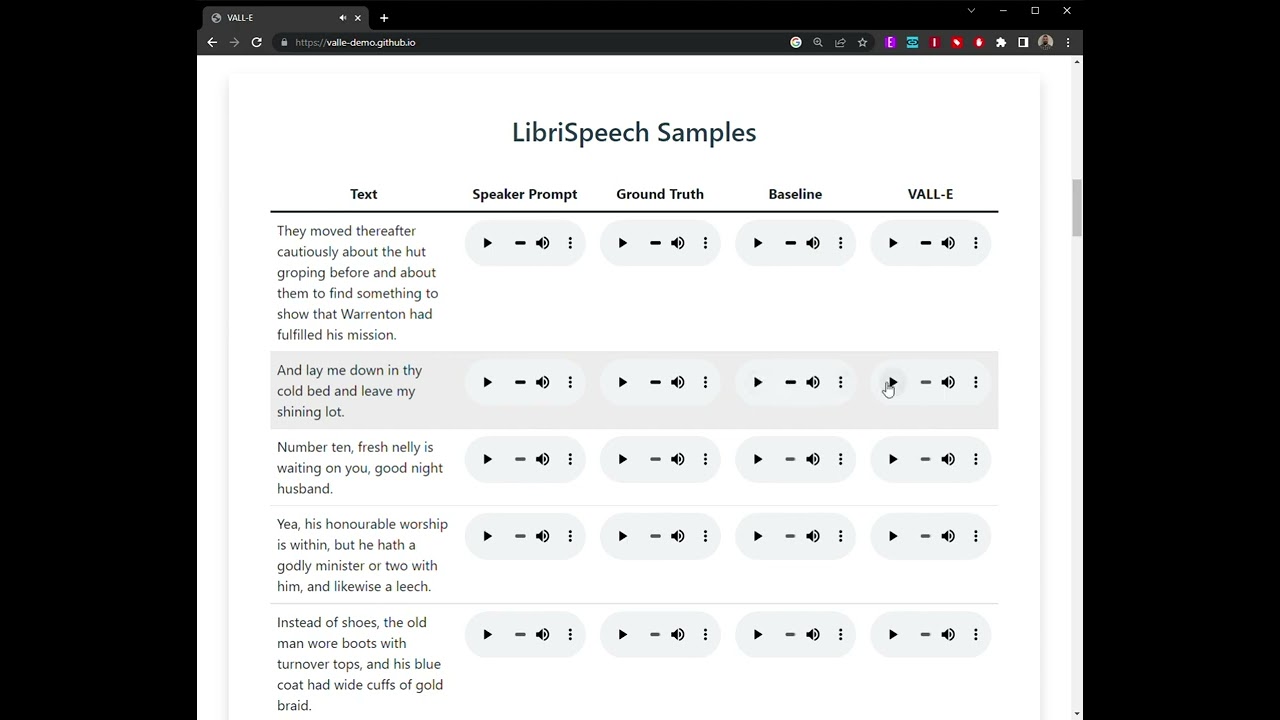
If you’re interested in seeing just how realistic VALL-E’s personalized speech is, you should check out the demo on GitHub as it has dozens of audio samples of the AI in action (shown in the video above). In these samples, the “Speaker Prompt” is the original three-second audio clip while the “Ground Truth” is a recording of this same speaker saying a particular phrase. Meanwhile, the “Baseline” is an example of another text-to-speech synthesis model and the “VALL-E” sample is the one generated by Microsoft’s new AI model.
Another interesting thing about VALL-E is that it can imitate the “acoustic environment” of the three-second clips used to impersonate people’s voices. This means that if the original speaker was in their car or on a phone call, the AI model will produce speech with those same acoustic characteristics.
VALL-E won’t be used in deepfakes anytime soon

Deepfakes have the potential to turn our world on its head as we’ll no longer be able to know for sure whether the video or audio clips we see are genuine. This is why, unlike with ChatGPT, Microsoft hasn’t nor does it have any plans to make VALL-E generally available.
The software giant has also ensured that a detection model can be built to tell whether or not an audio clip was created by its new AI model. At the same time, Microsoft has promised to put its AI principles “into practice when further developing the models”.

