
Luma Labs, the artificial intelligence company that previously put out the Genie generative 3D model, has entered the world of AI video with Dream Machine — and it is impressive.
Demand to try Dream Machine overloaded Luma's servers so much they had to introduce a queuing system. I waited all night for my prompts to become videos, but the actual "dreaming" process takes about two minutes once you reach the top of the queue.
Some of the videos shared on social media from people given early access seemed too impressive to be real, cherry picked in a way you can with existing AI video models to show what they do best — but I've tried it and it is that good.
While it doesn't seem to be Sora level, or even as good as Kling, what I've seen is one of the best prompt following and motion understanding AI video models yet. In one way it is significantly better than Sora — anyone can use it today.
Each video generation is about five seconds long which is nearly twice as long as those from Runway or Pika Labs without extensions and there is evidence of some videos with more than one shot.
What is it like to use Dream Machine?
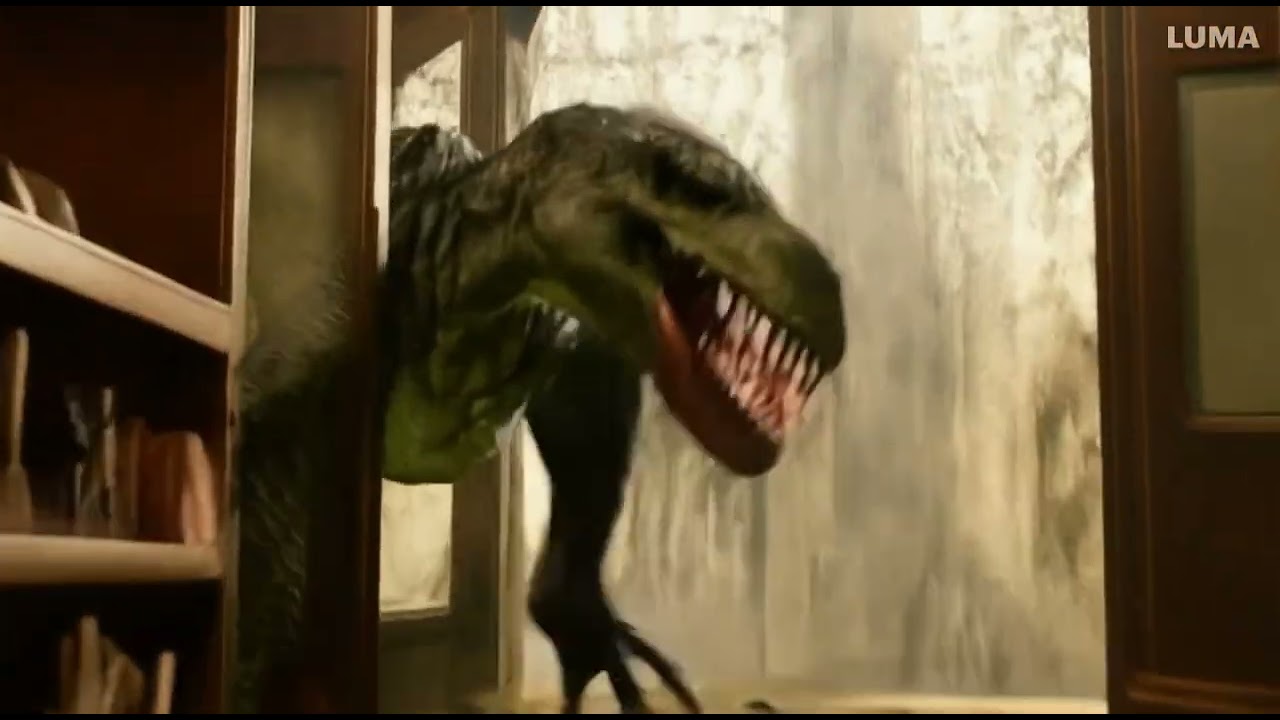
I created several clips while testing it out. One was ready within about three hours, the rest took most of the night. Some of them have questionable blending or blurring, but for the most party they capture movement better than any model I've tried.
I had them showing walking, dancing and even running. Older models might have people going backwards, or have a dolly zoom on a dancer standing still from prompts requesting that type of motion. Not Dream Machine.
Dream Machine captured the concept of the subject in motion brilliantly with no need to specify the area of motion. It was particularly good at running. But you have minimal fine-tuned or granular control beyond the prompt.
This may be because it's a new model but everything is handled by the prompt — which the AI automatically improves using its own language model.
This is a technique also used by Ideogram and Leonardo in image generation and helps offer a more descriptive explanation of what you want to see.
It could also be a feature of video models built on transformer diffusion technology rather than straight diffusion. Haiper, the UK-based AI video startup also says its model works best when you let the prompt do the work and Sora is said to be little more than a simple text prompt with minimal additional controls.
Putting Dream Machine to the test

I came up with a series of prompts to test out Dream Machine. For some of these I've also tried them with existing AI video models to see how they compare and none of them achieved the level of motion accuracy or realistic physics.
In some cases I just gave it a simple text prompt, enabling the enhance feature. For others I prompted it myself with a longer prompt and in a couple of cases I gave it an image I'd generated in Midjourney.
1. Running for an ice cream

For this video I created a longer form and descriptive prompt. I wanted to create something that looked like it was filmed on a smartphone.
The prompt: "An excited child running towards an ice cream truck parked on a sunny street. The camera follows closely behind, capturing the back of the child’s head and shoulders, their arms swinging in excitement, and the brightly colored ice cream truck getting closer. The video has a slight bounce to mimic the natural movement of running while holding a phone."
It created two videos. The first made it look like the ice cream truck was about to run the child over, and the arm movements on the child were a bit weird.
The second video was much better. Certainly not realistic and had an impressive motion blur. The video above was of the second shot as it also captured the idea of a slight bounce in camera motion.
2. Enter the dinosaur
This time I just gave Dream Machine a simple prompt and told it not to enhance the prompt, just take what it is given. It actually created two videos that flow from one another, as if they were the first and second shot in a scene.
The prompt: "A man discovers a magic camera that brings any photo to life, but chaos ensues when he accidentally snaps a picture of a dinosaur."
While there is a bit of warping, particularly on the fringes, the motion of the dinosaur crashing the room appreciates real-world physics in an interesting way.
3. Phone in the street

Next up a complex prompt again. Specifically one where Dream Machine has to consider light, shaky movement and a relatively complex scene.
The prompt: "A person walking along a busy city street at dusk, holding a smartphone vertically. The camera captures their hand as they swing it slightly while walking, showing glimpses of shop windows, people passing by, and the glow of streetlights. The video has a slight handheld shake to mimic the natural movement of holding a phone."
This could have gone two ways. The AI could have captured the view from the camera in the persons hand, or captured the person walking while holding the camera — first versus third person. It opted for a third-person view.
It wasn't perfect with some warping on the fringes but it was better than I'd have expected given the elements of inconsistency in my prompt.
4. Dancing in the dark

Next up I started with an image generated in Midjourney of a dancer in silhouette. I've tried using this with Runway, Pika Labs and Stable Video Diffusion and in each cases it shows movement into the shot but not of the character moving.
The prompt: "Create a captivating tracking shot of a woman dancing in silhouette against a contrasting, well-lit background. The camera should follow the dancer's fluid movements, maintaining focus on her silhouette throughout the shot."
It wasn't perfect. There was a weird warping of the leg as it spins and the arms seem to combine with the fabric, but at least the character moves. That is a constant in Luma Dream Machine — it is so much better at motion.
5. Cats on the moon

One of the first prompts I try with any new generative AI image or video mode is "cats dancing on the moon in a spacesuit". It is weird enough to not have existing videos to draw from and complex enough for video to struggle with motion.
My exact prompt for Luma Dream Machine: "A cat in a spacesuit on the moon dancing with a dog." That was it, no refinement and no description of motion type — I left that to the AI.
What this prompt showed is that you do need to give the AI some instruction in how to interpret motion. It didn't do a bad job, better than the alternative currently available models — but far from perfect.
6. Visiting the market

Next up was another one that started with a Midjourney image. It was a picture showing a bustling European food market. The original Midjourney prompt was: "An ultra-realistic candid smartphone photo of a bustling, open-air farmers market in a quaint, European town square."
For Luma Labs Dream Machine I simply added the instruction: "Walking through a busy, bustling food market." No other motion command or character instruction.
I wish I'd been more specific about how the characters should move. It captured the motion of the camera really well but it resulted in a lot of warping and merging between people in the scene. This was one of my first attempts and so hadn't tried out better techniques for prompting the model.
7. Ending the chess match

Finally, I decided to throw Luma Dream Machine a complete curveball. I'd been experimenting with another new AI model — Leonardo Phoenix — which promises impressive levels of prompt following. So I created a complex AI image prompt.
Phoenix did a good job but that was just an image, so I decided to put the exact same prompt into Dream Machine: "A surreal, weathered chessboard floating in a misty void, adorned with brass gears and cogs, where intricate steampunk chess pieces - including steam-powered robot pawns."
It pretty much ignored everything but the chess board and created this surrealist video of chess pieces being swept off the end of the board as if they were melting. Because of the surrealism element I can't tell if this was deliberate or a failure of its motion understanding. It looks cool though.
Final thoughts
I just did the following calculation:I had access to Luma Dream Machine on Saturday evening, and over 2-3 days of playing with it, I made 633 generations. Among these 633, I think at least 150 were just random tests for fun. So, I would estimate that it took me about 500… https://t.co/TpMCdDmlxyJune 12, 2024
Luma Labs Dream Machine is an impressive next step in generative AI video. It is likely they've utilized experience in generative 3D modelling to improve motion understanding in video — but it still feels like a stop gap to true AI video.
Over the past two years AI image generation has gone from a weird, low-res representation of humans with multiple fingers and faces looking more like something Edvard Munch might paint than a photograph to becoming near indistinguishable from reality.
AI video is much more complex. Not only does it need to replicate the realism of a photograph, but have an understanding of real world physic and how that impacts motion — across scenes, people, animals, vehicles and objects.
For now I think even the best AI video tools are meant to be used alongside traditional filmmaking rather than replace it — but we are getting closer to what Ashton Kutcher predicts is an era where everyone can make their own feature length movies.
Luma Labs have created one of the closest to reality motion tools I've seen yet but it is still falling short of what is needed. I don't think it is Sora level, but I can't compare it to videos I've made myself using Sora — only what I've seen from filmmakers and OpenAI themselves and these are likely cherry picked from hundreds of failures.
Abel Art, an avid AI artist who had early access to Dream Machine has created some impressive work. But he said he needed to create hundreds of generations just for one minute of video to make it coherent and once you discard unusable clips.
His ratio is roughly 500 clips for 1 minute of video, with each clip at about 5 seconds he's discarding 98% of shots to create the perfect scene.
I suspect the ratio for Pika Labs and Runway is higher and reports suggest Sora has a similar discard rate, at least from filmmakers that have used it.
For now I think even the best AI video tools are meant to be used alongside traditional filmmaking rather than replace it — but we are getting closer to what Ashton Kutcher predicts is an era where everyone can make their own feature length movies.
More from Tom's Guide
- Apple is bringing iPhone Mirroring to macOS Sequoia — here’s what we know
- iOS 18 supported devices: Here are all the compatible iPhones
- Apple Intelligence unveiled — all the new AI features coming to iOS 18, iPadOS 18 and macOS Sequoia











